Blink: Fast Connectivity Recovery Entirely in the Data Plane
Blink is the first data-driven fast reroute framework that works upon remote transit outages. Remote outages are challenging because they can happen in any network, at any time, and can affect any set of destinations. As the Internet converges slowly, remote outages often result in downtime for users.
Blink leverages the emerging programmable switches to detect remote failures directly in the data plane by looking at TCP-induced signals. Upon detection of a failure, Blink quickly restores connectivity by rerouting traffic to working backup paths, at line rate.
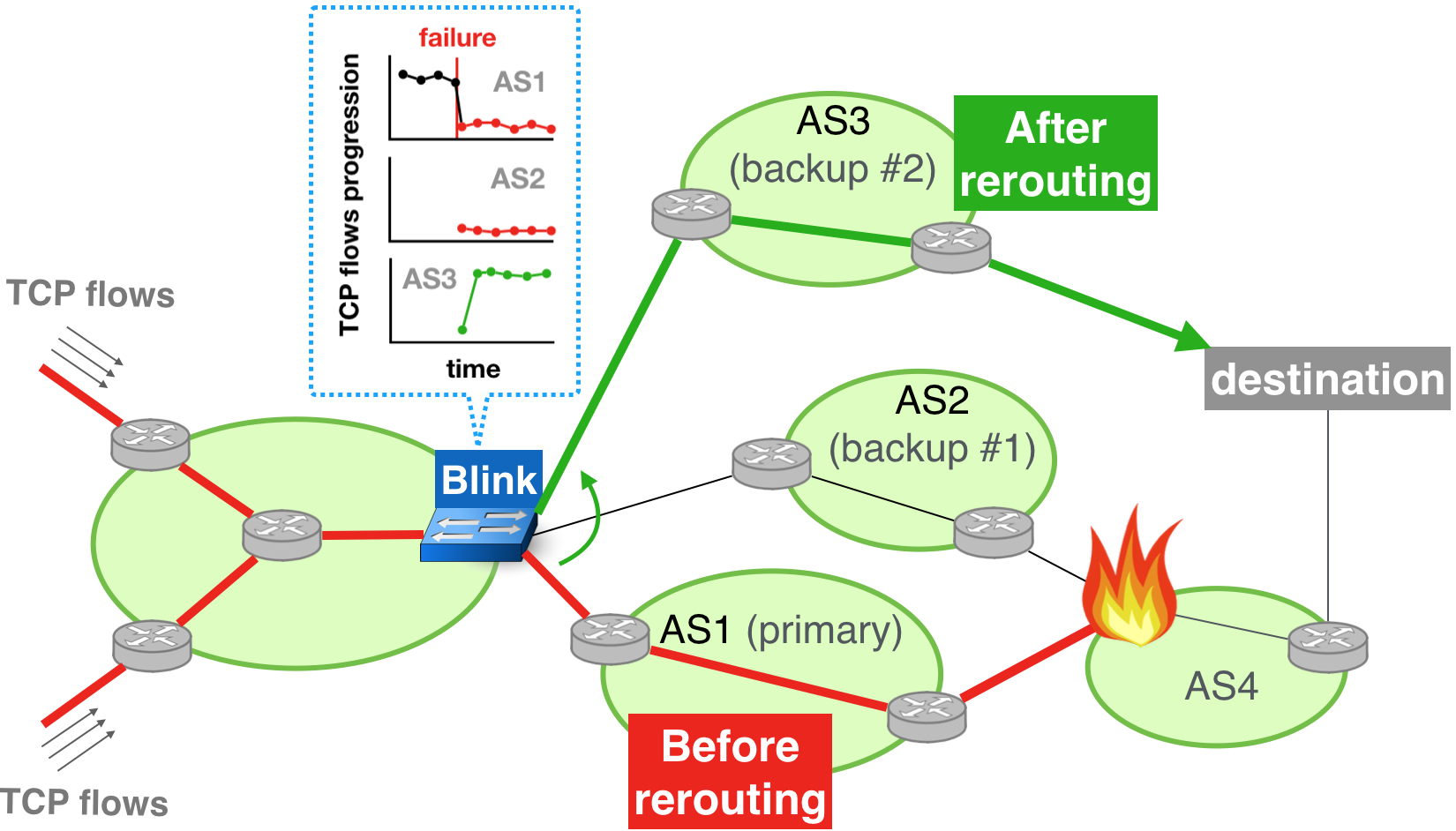

Upon a remote failure, data-plane signals are faster than the control-plane ones.
It can take O(minutes) to receive the first sign of a failure from the control plane
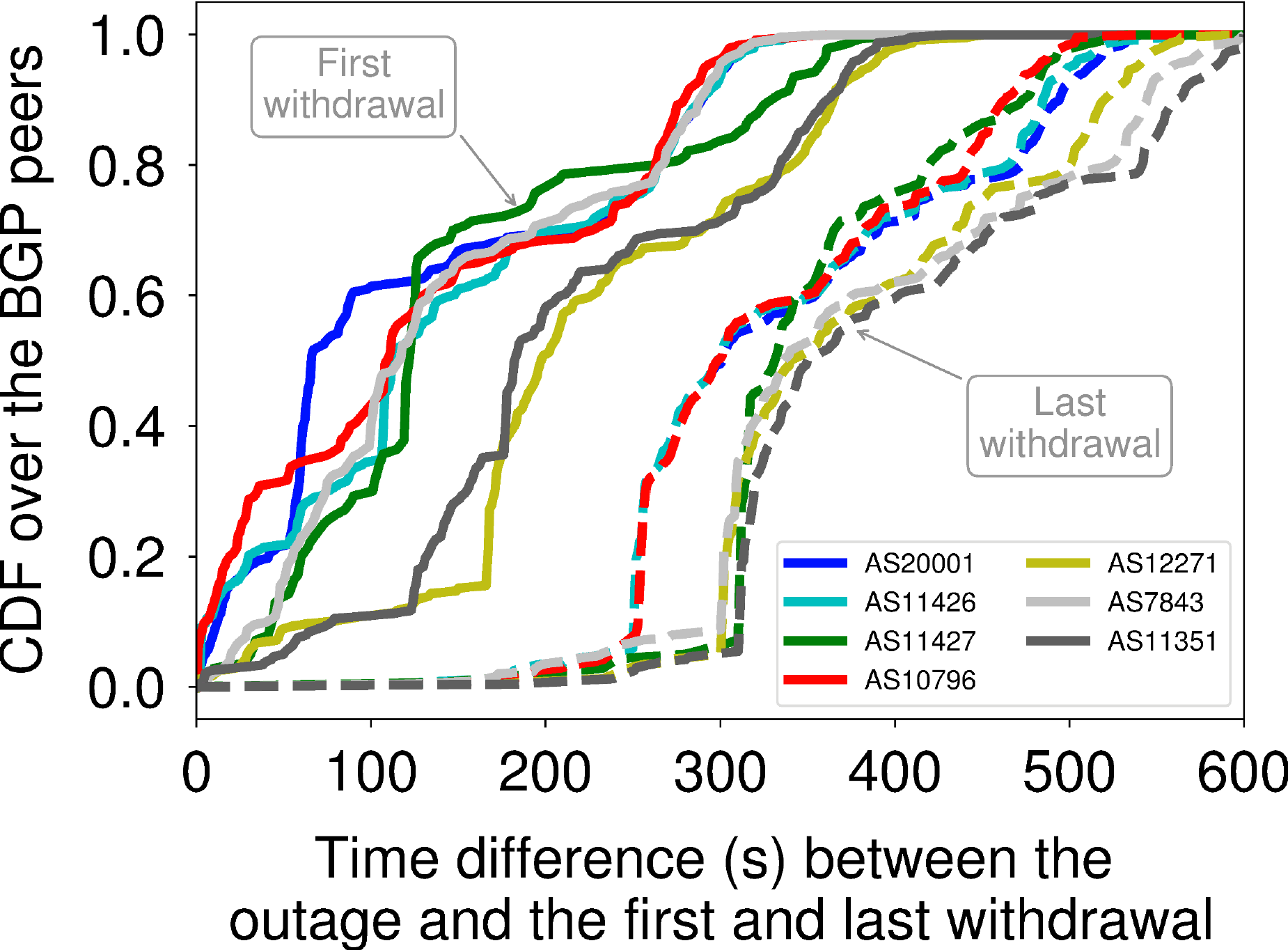
We illustrate the slow control-plane convergence through a case study, by measuring the time the first BGP updates took to propagate after the Time Warner Cable (TWC) networks were affected by an outage on August 27 2014. The Figure on the right depicts the CDFs of the time difference between the outage and the timestamp of the first BGP withdrawal each BGP peer from RIPE RIS and RouteViews received from each TWC AS after the outage. More than half of the BGP peers took more than a minute to receive the first update (continuous lines). In addition, the CDFs of the time difference between the outage and the last prefix withdrawal for each AS, show that BGP convergence can be as slow as several minutes (dashed lines).
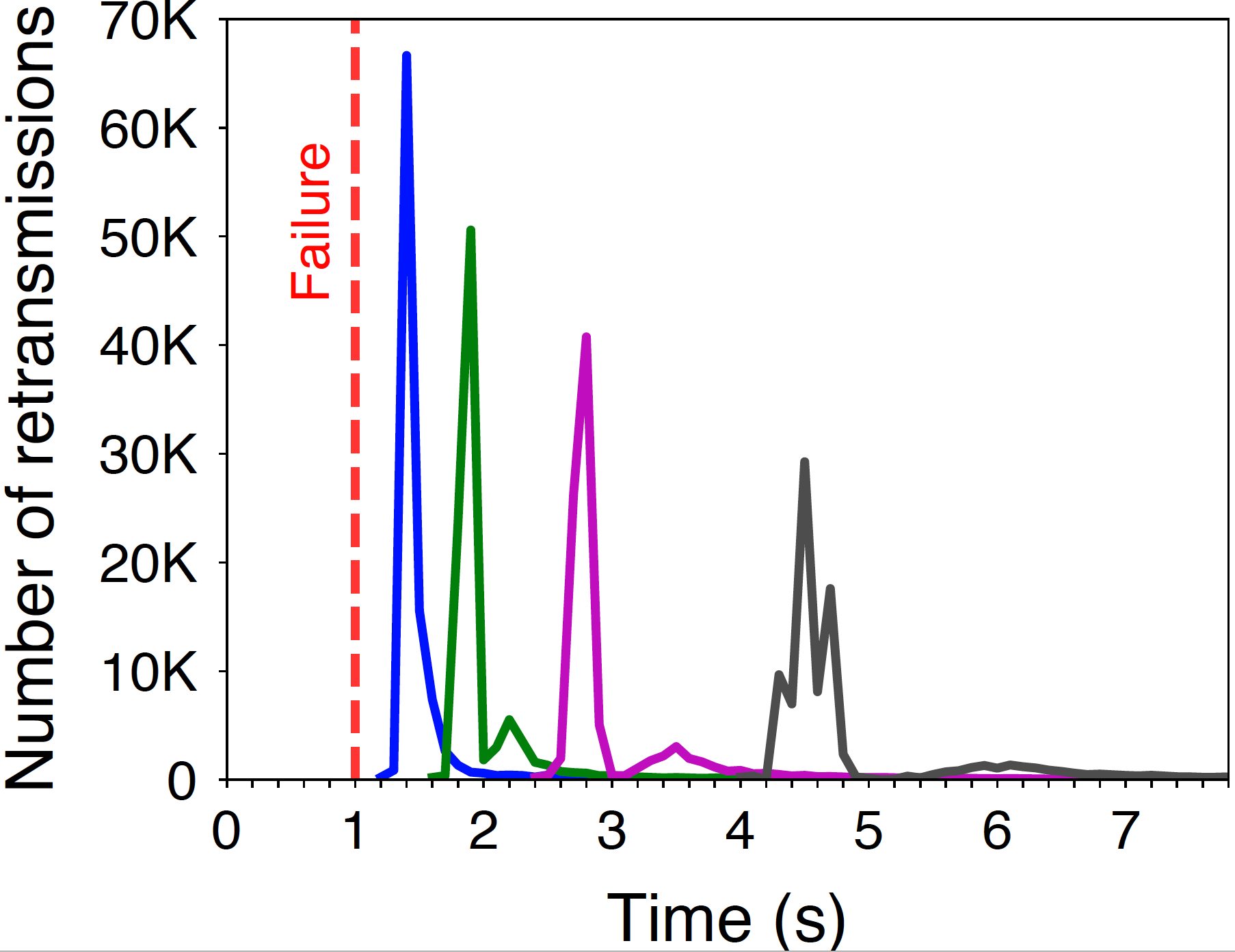
TCP flows exhibit a quick and pronounced behavior upon a remote outage
Upon an outage, the retransmission timer of a TCP source will eventually expire, triggering it to retransmit the first unacknowledged packet, again and again, following an exponential backoff. As this behavior is shared between all the TCP flows, when multiple flows experience the same failure, the signal obtained by counting the overall retransmissions consists of “retransmission waves”. The Figure on right shows the retransmission count for a trace that we generated with the ns-3 simulator after simulating a link failure. We can clearly see that first retransmissions quickly arrive after the failure, and most of them within a short period of time. Blink leverages this signal to quickly infer failures in the data plane.
Blink quickly recovers connectivity by rerouting based on data-plane signals
Accurate failure inference
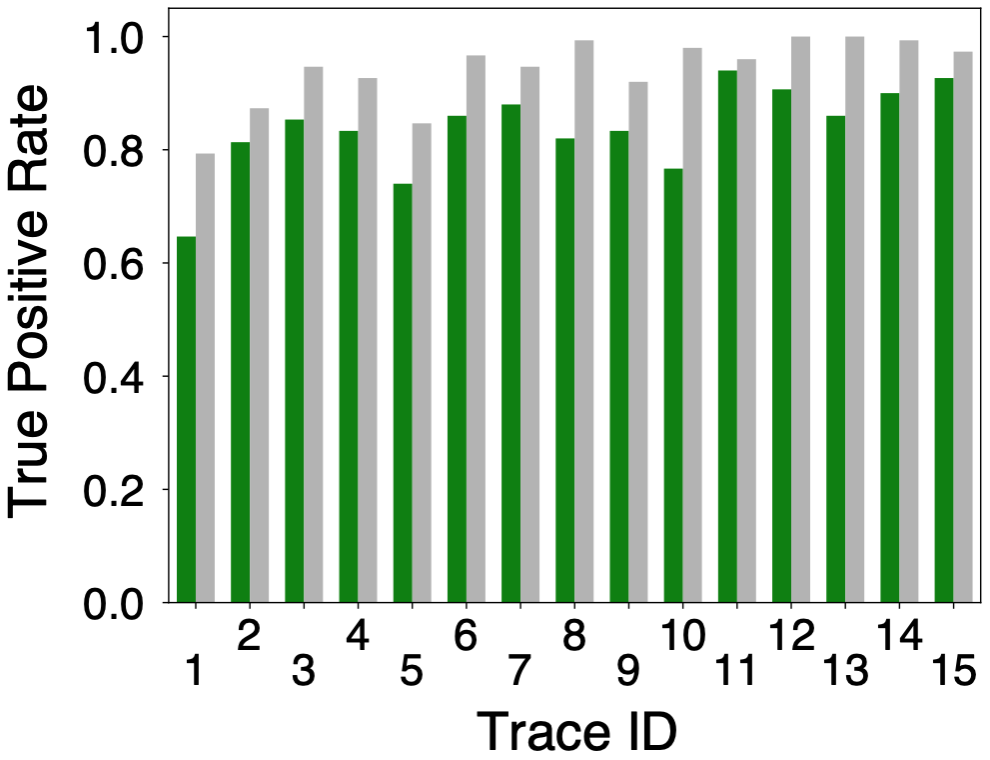
Blink looks at consecutive TCP retransmissions with the same next expected sequence number and on a per-prefix bases to infer failures. To fit in a programmable switch with limited resources, Blink monitors a sample of active flows for each monitored prefix. For a better accuracy, Blink uses a sliding window to count the number of flows experiencing retransmissions over time. Whenever the majority of the flows destined to a given prefix experience retransmissions within a time window, Blink infers a failure for that prefix. The Figure below shows the True Positive Rate of Blink as a function of the traffic pattern extracted from 15 real traffic traces. Blink can achieve more than 80% of True Positive Rate for most of the traffic patterns (green bars), and is close to an "upper bound" strategy of Blink (gray bars) which monitors all the flows instead of just a sample.
Quick connectivity recovery
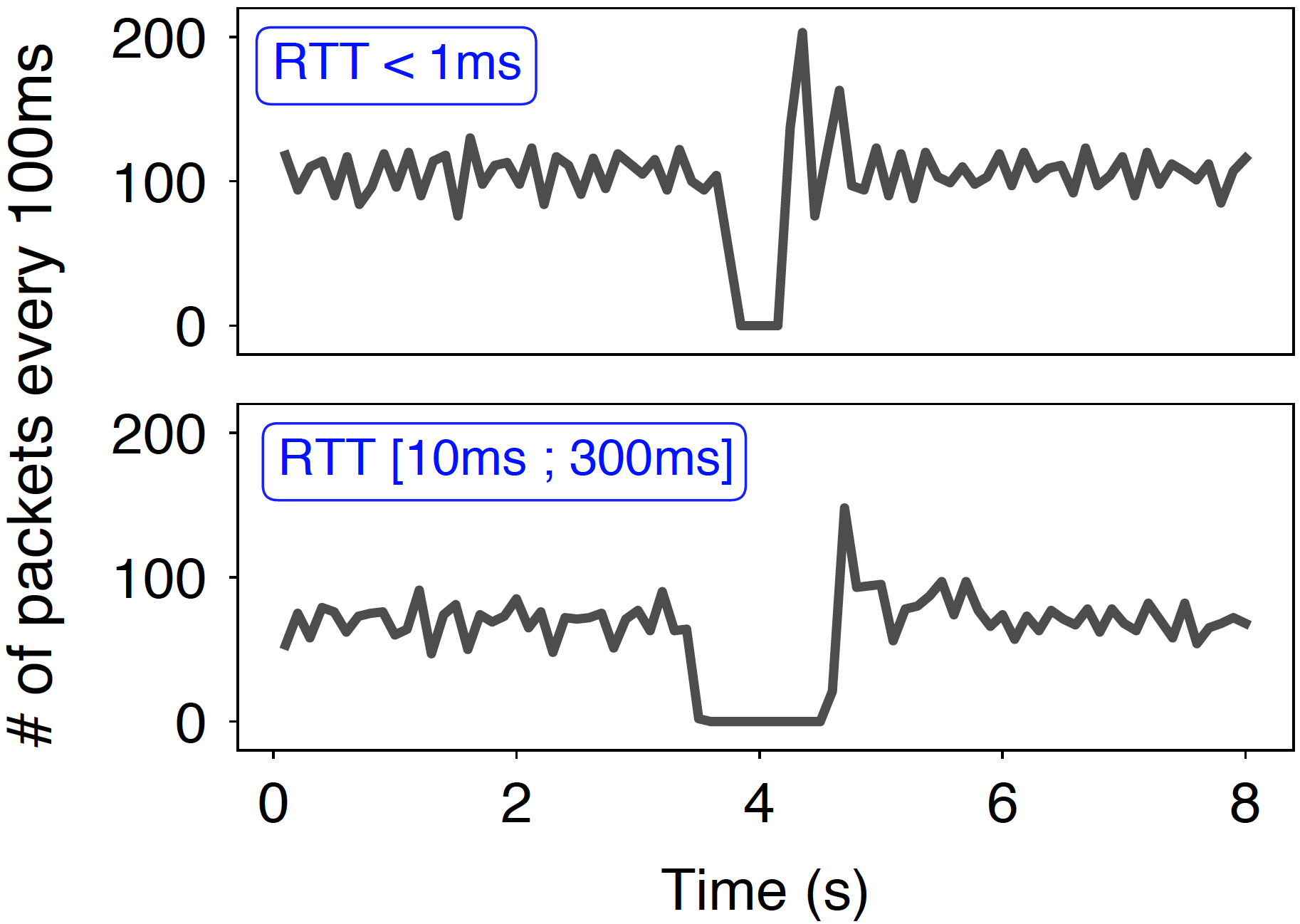
Whenever Blink detects a failure, it immediately activates, at line rate, backup paths that are pre-populated by the control-plane. As the rerouting is performed entirely in the data plane, Blink cannot avoid forwarding issues such as blackholes or loops. The good news is that upon rerouting, Blink sends few of the monitored flows to each backup next-hop during a short period of time and use them to assess (similarly than to detect failures) which one is working. After this period, Blink reroutes all the traffic to the best and working backup next-hop. To illustrate how fast is Blink at rerouting traffic, we ran it on a Barefoot Tofino switch, and measured how fast it can restore connectivity upon a failure. The figure below shows that the Tofino switch was able to restore connectivity via a backup link within 460ms with sub-1ms RTT and 1.1s with RTTs ranging from 10ms to 300ms.
Publications
Blink: Fast Connectivity Recovery Entirely in the Data Plane, NSDI'19. Boston, USA. February, 2019.
(paper, bibtex)by Thomas Holterbach, Edgar Costa Molero, Maria Apostolaki, Stefano Vissicchio, Alberto Dainotti, Laurent Vanbever
Presentations
NSDI 2019 (February 2019)
by Thomas Holterbach
Try it out!
We provide all the materials required to run Blink in a virtual environment.
This includes the implementation of Blink in P4_16,
a set of scripts and tools to easily build a VM using
vagrant and run a mininet-based network with p4 switches,
as well as the instructions to run Blink.
All of this is publicly available on
GitHub.
We release a Python-based implementation of Blink.
You can use our implemetation to try Blink on
traffic traces and quickly see how it would perform.
The source code is also publicly available
on GitHub.
People
- Thomas Holterbach, ETH Zürich,
thomahol at ethz dot ch - Edgar Costa Molera, ETH Zürich,
cedgar at ethz dot ch - Maria Apostolaki, ETH Zürich,
apmaria at ethz dot ch - Stefano Vissicchio, University College London,
s.vissicchio at cs dot ucl dot ac dot uk - Alberto Dainotti, CAIDA, UC San Diego,
alberto at caida at org - Laurent Vanbever, ETH Zürich,
lvanbever at ethz dot ch